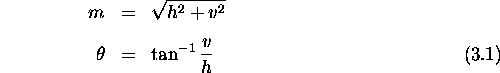Before we begin our consideration of landmark extraction, let us first consider the problem of edge detection. It has been shown that much of the essential information about a scene is contained in the edge map of the image [1], and that edge structures have an apparent relevance in biological vision systems [41]. In addition, the edge information in an image tends to be robust under changes in illumination or related camera parameters. For these reasons, edge structure has been used extensively in computational vision.
There are a variety of edge detectors available to researchers. Longi provides a succinct review of the more significant approaches [38]. For example, Marr and Hildreth convolve a mask over the image and label zero-crossings of the convolution output as edge points [42]. Gregson uses a combination of contrast thresholding and an analysis of direction dispersion to find edges [23]. Baker and Binford, and Ohta and Kanade label peaks in the magnitude of the first derivative of the intensity profile along a scan-line as feature points for matching [4, 46]. The Haralick edge operator employs a step-edge detector based on the second directional derivative [25]. Other popular gradient edge detectors are the Roberts, Sobel and Prewitt operators [5]. For the purposes of this work, we have selected an edge detector proposed by Canny and improved upon by Deriche [14, 17].
The Canny-Deriche operator initially identifies candidate edge pixels
through a set of edge-detection criteria; the image is convolved with
two square masks, producing estimates of the horizontal h
and vertical v
components of the brightness gradient at every pixel. The intensity
gradient at each pixel location can then be estimated by taking the
linear combination of these directional values, providing an estimated
magnitude m and direction ![]() (Eqn 3.1).
(Eqn 3.1).
For all pixels, ``non-maximum suppression'' based on the gradient magnitude is performed by exploring in the direction of steepest gradient. A pixel is kept as a possible edge point only if it has a larger gradient than its neighbours located in the direction closest to that of the gradient, and than its neighbours located in the opposite direction. The remaining local maxima belong to one-pixel-wide edge segments. Thresholding based on gradient magnitude is then performed on these points. Any point above a high threshold is kept, as well as any segment connected to it which consists of points above a lower threshold, reducing the probability of subdividing a segment whose magnitude fluctuates near the high threshold. Canny proves this approach to be optimal solution for image edge-detection under certain conditions [14, 17].